


Durch die mediale Omnipräsenz von künstlicher Intelligenz ist der Druck auf die Softwarebranche gewachsen, Produkte mit KI-Elementen anzubieten. Entwicklungsteams stehen vor der Herausforderung, ihre Produkte um KI-Komponenten zu erweitern und dabei sowohl ihr Produkt als auch die Endnutzer vor Angriffen zu schützen. Während bereits reguläre Maßnahmen zur Erhöhung der IT-Sicherheit für viele Unternehmen eine Hürde darstellen, so ist das bei Software mit KI nochmals erschwert, da KI-Expertinnen und -Experten erst langsam anfangen, Sicherheitsfragen systematisch zu bearbeiten und ihre Erkenntnisse zu verbreiten.
Anzeige
In der Entwicklungsbranche mit ihren häufig agilen Prozessen hinkt oft die IT-Sicherheit der Feature-Entwicklung hinterher. OWASP, NIST AI RMF, Google CoSAI und andere versuchen, das zu ändern, die Umsetzung ist jedoch insbesondere für kleine und mittelständische Unternehmen eine Herausforderung. Sogar größeren Konzernen fällt es schwer, ihren Kunden klarzumachen, dass ein frühzeitiges und umfangreiches Investment in sichere KI langfristig einen Wettbewerbsvorteil darstellt. Dabei haben Konzerne eher die Möglichkeit, Entwicklerinnen und Entwickler für die Weiterbildung abzustellen oder externes Expertenwissen einzukaufen.
Umgekehrt fassen viele Kunden ihre Forderung nach intelligentem Verhalten als einfachen Feature Request auf, da KI bequem per API von externen Betreibern eingebunden werden kann. Aber nur weil eine API einfach zu benutzen ist, heißt das nicht, dass das Endprodukt damit automatisch sicher ist.
Der EU AI Act hilft Sicherheitsverantwortlichen bei der Risikobewertung innerhalb der EU. Er geht auf die Problematik multimodaler KI-Modelle ein, wobei er speziell das Thema Datenfusion und die damit verbundenen Datenschutzprobleme regelt. Beratern liefert er auch ein Motiv, mit dem sie Kunden davon überzeugen können, ein KI-Projekt sorgsam zu planen: Denn er gilt für alle Anbieter von KI-Systemen auf dem europäischen Markt und sieht Strafen bis zu vierzig Millionen Euro oder sieben Prozent des weltweiten Jahresumsatzes vor. Ob und in welchem Umfang das jeweilige System unter den EU AI Act fällt, lässt sich online prüfen. Dieses Tool gibt auch Hinweise auf besondere Anforderungen, wie eine Pflicht zur maschinenlesbaren Kennzeichnung für KI-generierte Ergebnisse.
Außerdem definiert der AI Act, welche KI-Anwendungen im Europäischen Wirtschaftsraum zulässig sind. Auch das sollte ein Unternehmen bei Kundenanforderungen kritisch hinterfragen, da andernfalls ein Beratungsfehler vorliegen könnte, für den das beratende Unternehmen haftbar ist.
Da KI-Regularien derzeit noch im Entstehen sind, sollten Entwicklerinnen und Entwickler darauf achten, dass sich alle KI-Funktionen schnell abschalten lassen, ohne das Produkt zu blockieren.
Grundsätzlich lässt sich ein Softwareprodukt auf zwei Arten um künstliche Intelligenz erweitern: als Eigenentwicklung oder über ein externes KI-Angebot. Gemeinsam ist beiden, dass die genaue Entscheidungsfindung im KI-Modell unklar bleibt. Es arbeitet als Black Box, das heißt, es ist zwar grundsätzlich bekannt, wie KI-Modelle funktionieren, die genaue Entscheidungsfindung ist jedoch verborgen. Die Ergebnisse sind nicht fehlerfrei und die Gründe für ein bestimmtes Ergebnis nicht immer nachvollziehbar.
Security-Architekten betrachten KI – stark vereinfacht – als ein Modul mit eigenem Input, Output und einer Datenverarbeitung (siehe Abbildung 1). Bei allen drei Aspekten ist die Datensicherheit relevant, die im Fall einer KI zusätzlich das zugrunde liegende Modell, die Trainingsdaten und den physischen Speicher umfasst. Ein weiterer wesentlicher Aspekt ist die Verfügbarkeit der KI. Die fällt zwar in den Verantwortungsbereich des DevOps-Teams, Entwickler sollten jedoch bedenken, dass ein Ausfall zu unkontrolliertem Verhalten einer Software führen kann, was Angreifer ausnutzen können. Die Teams sollten Methoden für den Fall entwickeln, dass die KI keinen verwertbaren Output mehr erzeugt. Dabei sollten sie sich keinesfalls nur auf die Fehlerbehandlung der KI selbst oder die des KI-Providers verlassen, da deren Fehlerbehandlung ebenfalls ausgefallen oder manipuliert sein könnte.
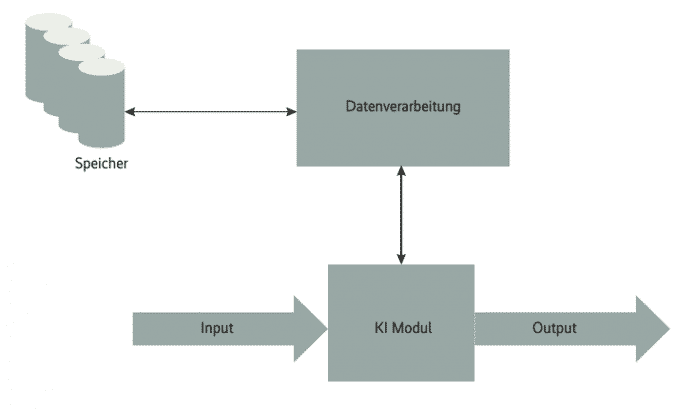
Vereinfachte Ansicht eines KI-Moduls: Es besteht aus Input, Output und einer Datenverarbeitung (Abb. 1).
(Bild: iX)
Zusätzlich zur technischen Ebene müssen Projektteams juristische Konsequenzen beachten, insbesondere, wenn Nutzer- oder Firmendaten an externe Provider gehen, womöglich ins Ausland. Dieser speichert Daten unter Umständen langfristig auf seinen Servern, auch für KI-Trainingszwecke. Erst kürzlich wurden Fälle bekannt, in denen Datenschutz in großem Stil verletzt wurde. Bei Anfragen an eine KI sollte das System daher grundsätzlich die transferierten Daten überprüfen. Eine Datenminimierung schont darüber hinaus die Ressourcen.
Bei der Einbindung einer externen KI müssen die Teams zusätzliche Aspekte beachten, beispielsweise für den Fall, dass ein Angreifer die Kontrolle über die Aus- und Eingaben erlangt hat. Das erfordert unter anderem automatische Sanity-Checks. Für Teams, die ihre KI selbst entwickeln, sind die Sicherheitsaspekte der Datenverarbeitung umfangreicher, da deren Sicherheit komplett in eigener Verantwortung liegt – was auch die Trainingsdatensätze und das Modell selbst umfasst. Neben der Sicherheit des physischen Speichers und der Server geht es darum, die Daten vor Diebstahl und Manipulation zu schützen. Berichte über Diebstähle gibt es bisher primär über interne Angreifer, sie sind jedoch grundsätzlich auch von externen Angreifern denkbar.
Die KI ist darüber hinaus vor fehlerhaften und boshaften Nutzereingaben zu schützen. Zum einen sind KIs grundsätzlich bezüglich der Dateneingaben empfindlich. Zum anderen handelt es sich meist um Multi-Tenancy-Systeme, bei denen ein Nutzer versuchen könnte, die Daten anderer abzugreifen. Beides erfordert Sanity-Checks für die Eingaben der Nutzer und den eigenen Input in die KI.
Mittlerweile existieren Hilfsmittel, die bei der Risikobewertung helfen, zum Beispiel die OWASP Top 10 LLM Applications & GenAI. Etwas umfangreicher, jedoch mit vielen praktischen Anleitungen ergänzt, steht ein Guide des Departments of Science, Innovation & Technology der UK-Regierung zur Verfügung. Vorgaben zur Umsetzung von Governance-Aufgaben stellt das National Institute of Standards and Technology (NIST) bereit.
Viele Lecks in KI-Systemen nutzen alte Probleme, die für sich genommen bereits bekannt sind: Fehlen von adäquaten Zugriffskontrollen und hinreichender Verschlüsselung, mangelhafte Authentifizierung aller Kommunikationsteilnehmer inklusive der Software-Module sowie die Definition, Validierung und das Sanitizing von Eingaben und Ausgaben. Häufig nutzen Angreifer nicht die KI-Module selbst als Ziel, sondern die bereitstellenden Systeme oder Webportale. Wesentlich seltener sind derzeit Risiken, die von der KI selbst und deren Black Box ausgehen. Hierbei geht es meist um Angriffe, die die Gütefunktion der KI manipulieren, das heißt, die beeinflussen, wie die KI Entscheidungen trifft. Diese Angriffe versuchen vor allem Trainingsdatensätze zu manipulieren oder bei adaptiven Systemen massive Mengen an korrumpierenden Daten einzugeben, um das System in eine gewünschte Richtung zu lenken [1]. Alle Schutzmaßnahmen sollten dauerhaft im Rahmen eines KI-Lifecycle-Managements getroffen und an den Software-Release-Cycle angeknüpft werden.
Der Input von Anfragen an die KI sollte stets eine klar definierte Struktur haben, die Anforderungen zur erwartenden Anfragenmenge, zur Anfragengeschwindigkeit und gegebenenfalls zu verwendeten Zeichen umfassen. Einige KI-Anbieter checken selbst den Inhalt von Anfragen, je nach Szenario kann dies aber auch innerhalb des eigentlichen Softwareproduktes sinnvoll sein, um Nutzer an der Eingabe sensibler Informationen zu hindern und um Prompt Hijacking oder Code Injections vorzubeugen. Es gilt jene Anfragen zu identifizieren, die die KI manipulieren oder sogar die Kontrolle über sie oder ihre Speicherbereiche übernehmen können. Aufgrund der Anwendungsvielfalt gibt es kein umfassendes Patentrezept dafür, gefährliche Anfragen zu erkennen. Entwicklerteams sollten für ihr Produkt überlegen, wie Angreifer die KI darin manipulieren könnten und wie sich dies verhindern lässt. Hierfür eignen sich beispielsweise Bad User Storys. Ein externer KI-Anbieter sollte dies im Idealfall bereits umgesetzt haben.
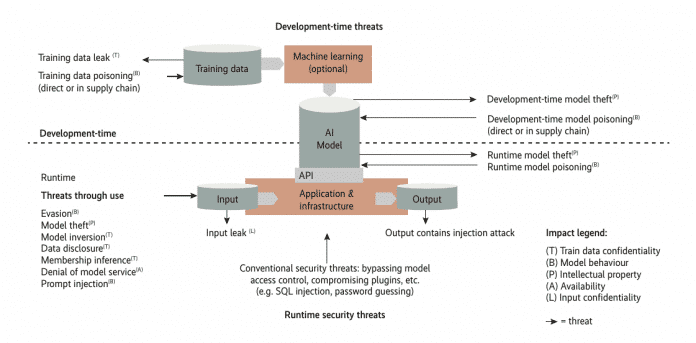
Die Angriffe auf ein KI-System zielen nicht nur auf die KI selbst, sondern auch auf die Infrastruktur und die Daten (Abb 2).
(Bild: OWASP AI Exchange/iX)
Dem Entwicklerteam sollte bei externen Providern zusätzlich bewusst sein, dass diese Daten der Endnutzerinnen und -nutzer erhalten, verarbeiten und oft speichern oder weiternutzen. Im Falle von Datenlecks kann der Nachweis relevant sein, ob diese Daten durch die eigene Software oder den KI-Provider geleakt sind. Ferner muss das Team an eine Verschlüsselung der Datenübertragung und eine Authentifizierung der involvierten Parteien denken. Leider zeigte sich in der Vergangenheit mehrfach, dass sich nicht alle KI-Unternehmen datenschutzkonform verhalten und ungenehmigt Daten zu KI-Trainingszwecken nutzten.
Mit speziellen Sicherheitsrisiken ist Multi Tenancy verbunden, insbesondere hinsichtlich der Isolation der Mandanten. Die Absicherung gehört zwar regulär nicht zu den Aufgaben der Entwicklerinnen und Entwickler, jedoch sollten sie sich der Risiken bewusst sein und Gegenmaßnahmen ergreifen können (zum Beispiel Authentifikation oder Verschlüsselung).
Entsprechend der Input-Kontrolle sollten die Entwicklungsteams die Ausgaben der KI klar definieren und sie auf Einhaltung dieser Spezifikation überprüfen. Ebenfalls sollte es Fail-safe-Routinen geben, die eingreifen, wenn die Ausgaben die Spezifikationen nicht erfüllen. Die Definition des zu erwartenden Outputs ist ebenso wie beim Input spezifisch und die Teams müssen sie in Abgleich mit den Kundenvorgaben festlegen. Entwicklerinnen und Entwickler sollten überlegen, wie Angreifer die KI dazu bringen können, unvorhergesehenen Output zu erzeugen, und was ein Risiko für Produkt und Endnutzer darstellt. Routinen sollten solches Verhalten abfangen. Auch das lässt sich im Team zum Beispiel durch Bad User Storys evaluieren.
Bekannte, generische Risiken entstehen beispielsweise durch zu lange, zu viele oder zu schnelle Antworten der KI: der Klassiker des Denial of Service. Auch Antworten mit Sonderzeichen sollten Entwicklerinnen und Entwickler grundsätzlich abfangen, wenn sie nicht dem erwarteten Muster entsprechen. Das dient sowohl dem Schutz der Endnutzer als auch dem des eigenen Produktes, falls es mit den Antworten weiterarbeitet: Mögliche Gefahren sind Code Injections, Prompt Hijacking, Logic Bombs und viele weitere.
Grundsätzlich sollten die Teams automatisierte Use Cases entsprechend der vorhandenen Ressourcen beschränken. Ein einfaches Beispiel für einen Missbrauch ist die automatische massenhafte Versendung KI-generierter Mails. Für Endnutzer ist Output ein potenzielles Risiko, der zur Interaktion mit externen Quellen auffordert, beispielsweise zum Klicken externer Links oder zum Bezahlen von etwas. Entwicklerteams, die solche Use Cases haben, müssen die KI-Ausgabe mit zusätzlichen, von der KI unabhängigen Routinen kontrollieren.
Der EU AI Act schreibt eine weitere Anforderung an den Output vor: KI-generierter Content muss als solcher gekennzeichnet werden, um die Verbreitung von Deepfakes zu erschweren [2]. Angreifer können Deepfakes für Desinformationskampagnen auch über Schwachstellen in der KI ausspielen.
Ein Grundsatz der IT-Sicherheit lautet, wann immer Kommunikation erfolgt, sollte diese abgesichert sein, was auch für den Datenaustausch zwischen Softwarekomponenten gilt. Das ist insbesondere dann relevant, wenn Daten nicht nur lokal verarbeitet werden. Entwicklerteams sollten diesen Aspekt bei der Einbindung einer externen KI besonders berücksichtigen. Es ist sehr wahrscheinlich, dass ein Angreifer zunächst versucht, einen unsicheren Datenstrom abzugreifen oder zu manipulieren, bevor er gesicherte Server oder die KI selbst angreift.
Adaptive KIs können aus den Eingaben von Nutzern lernen, sodass sensible Daten in die Wissensbasis der KI gelangen und an andere Nutzer weitergegeben werden können. Dem können Entwicklerinnen und Entwickler nur durch penible Datensparsamkeit begegnen. Nutzerinnen und Nutzer sollten darauf aufmerksam gemacht werden, dass das KI-System die eingegebenen Daten verarbeitet und speichert. Sind solche Daten einmal in der KI aufgenommen, ist es eine Herausforderung, die Daten aus der Wissensbasis und dem Modell wieder vollständig zu entfernen.
Auch interne Datentransfers sollten bereits auf technischer Ebene nur die nötigsten Informationen bewegen. Das beinhaltet auch technische Daten. Entsprechende Konzepte sollten in die Anforderungsspezifikationen einfließen und mit jedem Release überprüft werden.
Das Thema Datensicherheit für KI-Anwendungen ist sehr breit. Entwicklerteams sollten klar definieren, welche Aspekte der Datensicherheit sie selbst abdecken können und welche nicht in ihrem Aufgabenbereich liegen. In diesem Fall sollten sie festlegen, wer dann verantwortlich ist (zum Beispiel der Service Provider) [3]. Die Klärung der Verantwortlichkeiten und Zugehörigkeit von Domänen ist ein wesentlicher Bestandteil der Sicherheits- und Risikoanalyse. Wichtig ist es auch, sich den Datenfluss zu vergegenwärtigen und im Rahmen regelmäßiger Analysen zu prüfen, ob Angreifer Daten abgreifen oder manipulieren können. Ein Verständnis des Datenflusses ist auch hilfreich, um die geforderte Transparenz gegenüber Endnutzern einzuhalten.
Eine maschinell lesbare Kennzeichnung von KI-generierten Daten zeigt, welchen Content reale Nutzer erstellt haben und welchen die KI. Das ist wichtig, um fehlerhaften KI-generierten Content identifizieren und das System bereinigen zu können. Es ermöglicht auch die Identifikation von KI-generierten Deepfakes und erlaubt das Nachvollziehen des KI-Datenfluss. Das erleichtert die Analyse von Datenlecks, Manipulationen und Desinformationskampagnen.
Forscher bemängeln seit geraumer Zeit die Unzulänglichkeiten beim Testen von KI-Systemen [4]. Oft benötigen Unternehmen dedizierte Software-Testerinnen und Tester mit KI-Erfahrung, die nicht leicht zu finden sind. Ansätze beim KI-Testing bestehen vor allem darin, sicherzustellen, dass das Endprodukt auch bei Fehlverhalten der KI vorhersagbar reagiert, nicht korrumpiert wird, und dass unzulässiges Verhalten sowie unzulässige Antworten der KI abgefangen werden.

(Bild: iX)
Dieser Artikel ist auch im iX/Developer-Sonderheft zu finden, das sich an Softwarearchitektinnen und Softwarearchitekten richtet. Neben den klassischen Architekturinhalten zu Methoden und Pattern gibt es Artikel zu Soziotechnischen Systemen, Qualitätssicherung oder zu Architektur und Gesellschaft. Domain Driven Design ist ebenso ein Thema wie Team Topologies und Sicherheit.
Als Autoren konnten wir bekannte Experten gewinnen, die ihr Wissen in vielen spannenden Artikeln – wie dem hier vorliegenden – sowohl für Architektureinsteiger als auch Spezialisten weitergeben.

Kommentare